in diesem Video
hat der Nutzer einen Text aus seinem Scan gemacht und dann bearbeitet. Bei mir klappt das ganze nicht so.
Wie kann ich, wie im Video zusehen, einen Text konsolidieren?

in diesem Video
hat der Nutzer einen Text aus seinem Scan gemacht und dann bearbeitet. Bei mir klappt das ganze nicht so.
Wie kann ich, wie im Video zusehen, einen Text konsolidieren?
Nutzer einen Text aus seinem Scan gemacht und dann bearbeitet.
Und genau das ist das, was in dem Video verschwiegen ist: “Wie erhalte ich dieses PDF, das hinter dem Image auch noch den Text enthält?”
In dem Video wird für mein Verständnis kein gescanntes PDF bearbeitet. Der bearbeitet einen normalen PDF Text, der von einem Image überlagert ist. Ein Scan erzeugt aber ein Bild und auch wenn dass als PDF gescannt und gespeichert wird, bleibt es ein Bild und das kannst Du nicht so bearbeiten, wie es da gezeigt wird. Du müsstest den Scan mit einem sogenannten OCR Programm (vor-) bearbeiten. Ein solches Programm ist (mehr oder weniger gut) in der Lage, aus Bilddaten den enthaltenen Text zu extrahieren, den man dann weiter bearbeiten kann. Manche Scan Programme können ein solches OCR Programm integrieren oder bringen selbst eines mit. Da musst Du dich beim Hersteller deines Scanners, deiner Scanner-Software und/oder im Handbuch des Scanners informieren, ob das möglich.
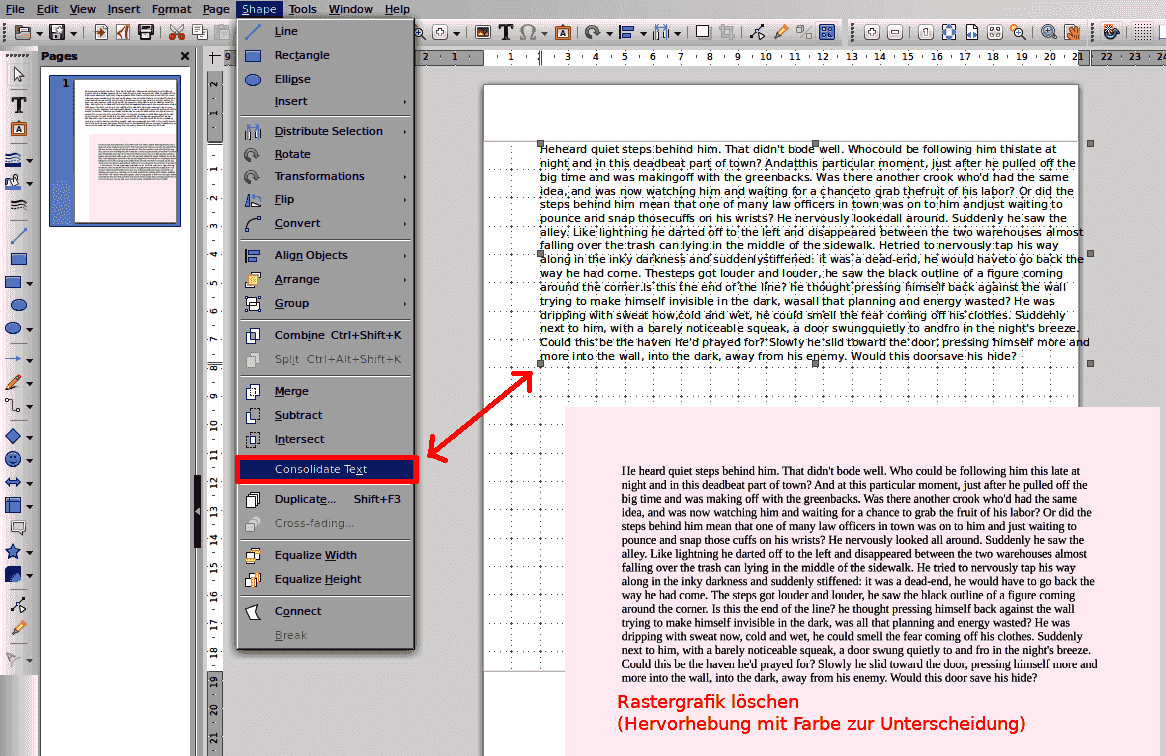
Wenn es so ist, wie @anon73440385 schreibt, dass dem gescannten Bild ein Text hinterlegt ist (das macht z.B. www.pdf24.org, wenn ein Bild als PDF im OCR-Mode gerippt wird), dann kann man den Text “herauslösen” (herauskopieren) oder das Bild löschen, wenn in Draw geöffnet wird. Siehe Bild… Der eigentliche Text kann dann markiert und konsolidiert werden.