Hello all,
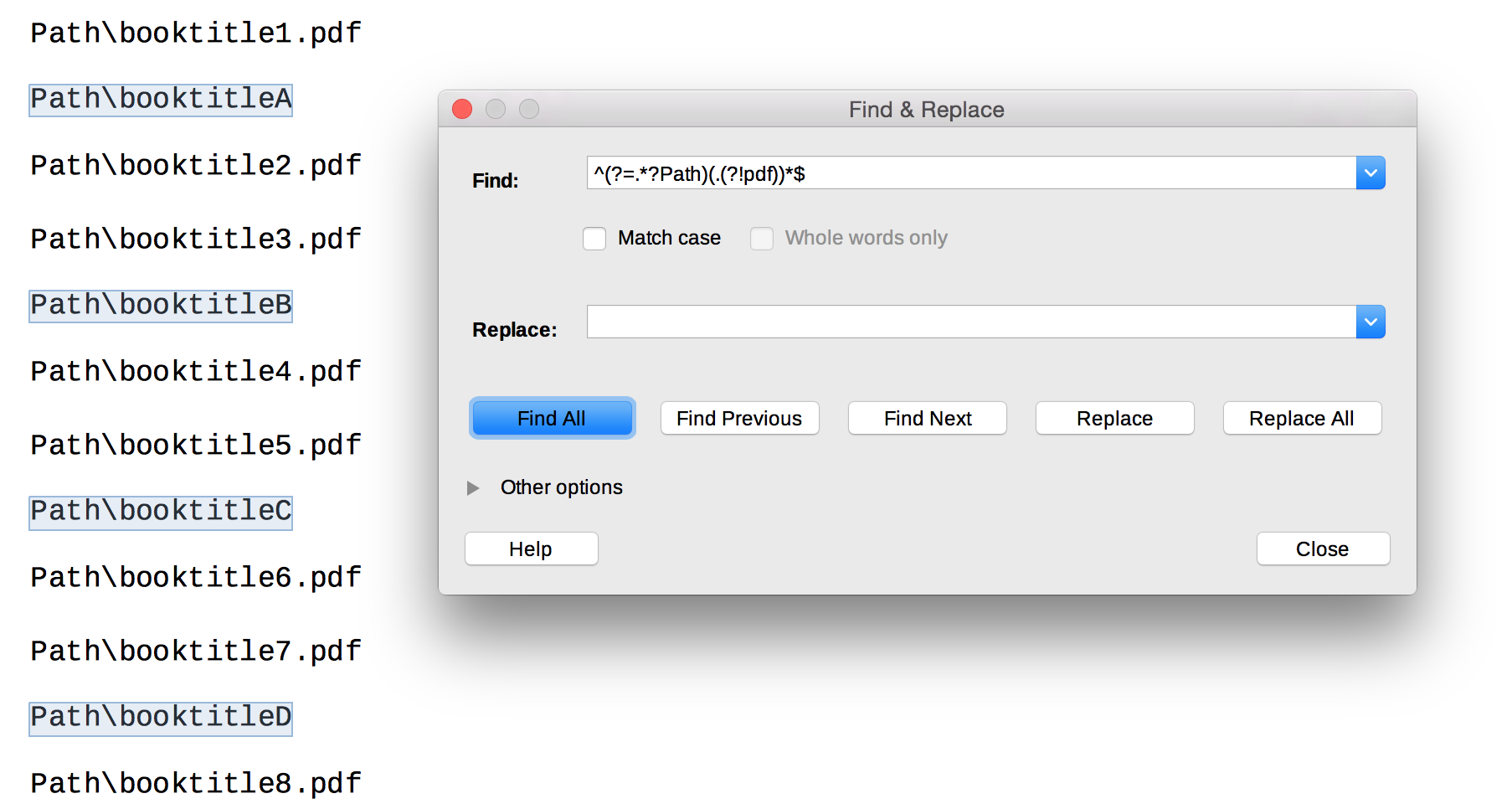
I have a long text with many paragraphs. Each paragraph is the path to a file or a directory. Some of the paths are to PDF files, like: Path\booktitle.pdf
I want to delete all paragraphs that do not contain the phrase .pdf so that I am left with a text containing just paths to books. Is there a clever way to do this in Writer? Or maybe Calc? There is a maximum of one .pdf per paragraph.
My version is LibreOffice 6.0.2.1
Many thanks,
Ruud