Hi doug, first thing, let me thank you for your help with those replies so accurate and detailed.
However, I think I did not explain myself well…
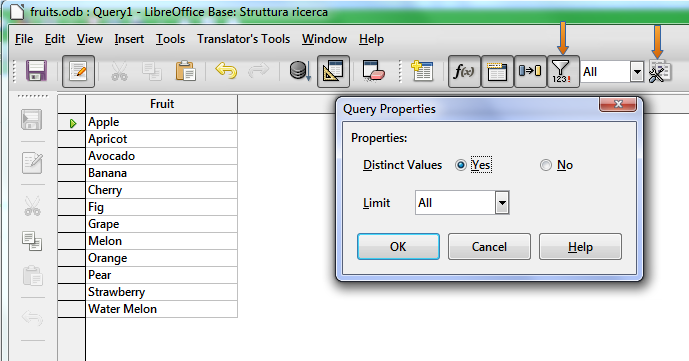
Yes, the group function it’s magic, allow us to remove duplicates from our query, so we won’t see the duplicated results…
However, I don’t want that.
What I want is… having one table (TABLE 1), creating a new table (TABLE 2), clean, with all the data from TABLE1 but not getting the duplicates values. So assuming we have TABLE1 with duplicated values, what I want is to get all the data from TABLE1, and not getting the duplicates, and creating a new table, TABLE2, clean, with all the data from TABLE1 except the duplicates…
I think I did not explain clearly. I’m sorry…
So, can we do this without using HSQLDB? If we could do this without HSQLDB… it would be great. If not… could you give me an example code in HSQLDB creating a new table with all the duplicates removed?
I did a very simple database with two tables.
Fruits
Fruits and Recollectors
The first table have only one field, with some fruits duplicated.
The second table have fruit and its recollector name (two fields), some of the registries are duplicated and other don’t.
Of course we are not analyzing the primery key, because each registry would be unique, we should analyze duplicates in all the fields except the primary key.
I have uploaded the database, so you can download it from here:
https://mega.co.nz/#!0EgwWS4D!_bmEtEuVdbK59jBcYDgsNht_XWFTjdGLRiWhF3boGZI
Could you give me a method to create a new table without the values duplicated or if this is impossible, at least, a sample code in HSQLDB with the duplicateds removed in the new table?
Cheers