
Hi there!
I am trying to find a formula that will find all the distinct values from a column where the values repeat in random order. The values are text.
I have found something for Excel but it gives me just empty cell.
And the “something for Excel” is …?
=IFERROR(INDEX($A$2:$A$10, MATCH(0, COUNTIF($B$1:B1,$A$2:$A$10) + (COUNTIF($A$2:$A$10, $A$2:$A$10)<>1), 0)), “”)
Where $A$2:$A$10 is the source list and $B$1:B1 is the column header where the formula is inserted starting from B2
Would you mind to explain what column is the one from which you want to get the distinct values, and what contents are expected to reside in the other column of the two occurring in the formula?
The above comment crossed mine in time. I cannot get a reasonable meaning, however.
Finally some explanation, thanks.
Fwiw, all the formula expressions given there work for me with the example of “Ronnie”;“David”;… if it doesn’t work in your case you’re likely doing something different (or you’re using an older version in which it doesn’t work, I tried 5.2 and 5.3)
@erAck: Suppose the formula was not entered for array-evaluation. As a one -cell-array-formula correctly filled down as far as needed it works for me.
I found a decent solution on reddit: Libre Calc - UNIQUE function like Excel not working by user: N0T8g81n
menu:File>New>Database…
[X] Connect to existing database
Type: Spreadheet
[X] Register database
Save the database document.
Nothing has been converted or copied. Your data are still in the spreadsheet.
Add a query to the database which includes the column(s) you want to be unique and check the “distinct” option. In design view, there is a “Distinct” toolbar button. In SQL view the query looks like this:
SELECT DISTINCT "Name", "Forename" FROM "Sheet1"
Add some sort order or filter if you like, save and close the database document.
Back to the Calc window, open the datasource window (Ctrl+Shift+F4) navigate to the new database and drag the query icon into the Calc document. This creates a link that can be refreshed via menu:Data>Refresh…
1 Like
UNIQUE() is now available (since LO version24.8):
https://help.libreoffice.org/latest/en-US/text/scalc/01/func_unique.html?DbPAR=CALC
Hello @adrianbucks, you could use a Filter to list, or copy, all the distinct rows from a range in Calc.
Manually:
1. Select the entire Range to find distinct rows in ( e.g. "A1:B99" ),
2. Choose the menu "Data : More Filters : Standard Filter...",
3. In the dialog box that appears, in the first row of the Filter Criteria, set the Field Name to "- none -",
4. Expand the Options by clicking on the small triangle,
5. Check the checkbox "No duplications",
6. Check the checkbox "Copy results to:" and enter a full Target CellAddress into the textbox ( e.g. "Sheet1.D1" ),
7. Uncheck the checkbox "Keep filter criteria",
8. If your source range does not contain a header, uncheck the checkbox "Range contains column labels",
9. If case matters while searching for distinct rows, check the checkbox "Case sensitive",
10. Click OK.
By Macro:
Sub filterDistinct( strSourceRange As String, strTargetCell As String, Optional bContainsHeader As Boolean, Optional bCaseSensitive As Boolean )
REM Uses a Filter to copy distinct rows from the specified Source Range into a new Range that starts from the specified Target Cell.
REM <strSourceRange> : specifies the Range to find distinct rows in, e.g. "A1:B99".
REM <strTargetCell> : specifies the Cell to put the first found distinct row in, e.g. "D1".
REM <bContainsHeader> : OPTIONAL - pass TRUE if the Source Range contains a Header.
REM <bCaseSensitive> : OPTIONAL - pass TRUE if case matters while searching for distinct rows.
Dim oSheet As Object, oSourceRange As Object, oFilter As Object
oSheet = ThisComponent.CurrentController.ActiveSheet
oSourceRange = oSheet.getCellRangebyName( strSourceRange )
oFilter = oSourceRange.createFilterDescriptor( True )
oFilter.SkipDuplicates = True
oFilter.CopyOutputData = True
oFilter.OutputPosition = oSheet.getCellRangebyName( strTargetCell ).CellAddress
If Not IsMissing( bContainsHeader ) Then oFilter.ContainsHeader = bContainsHeader
If Not IsMissing( bCaseSensitive ) Then oFilter.IsCaseSensitive = bCaseSensitive
oSourceRange.filter( oFilter )
End Sub
Example call : filterDistinct( “A2:A10”, “B2” )
2 Likes
I would suggest to not use convoluted formulae. Introducing a helper column which may be hidden in the working sheet makes things clear and simple, and avoids problems with maintenance, in specific with scaling and enhancements. A solution regarding this suggestion you find on Sheet2 of this attached demo. You dont need to permit macros to see how it works.
I also demonstrate a solution based on user functions on Sheet1 of the attached demo. As already said I would not recommend it though.
(Editing:)
Meanwhile I studied once more the “Excel-Formula” given in the OQ, as it does not contain anything that might be suspected to work differently in LibO Calc. The results:
1 - The formula is convoluted and will be rather inefficient (relevant only for much more rows).
2 - The formula can only work in a reasonable sense if entered for array-evaluation (Ctrl+Shift+Enter).
3 - Put into B2 the formula must be filled down into additional 9 cells. (If dragging: Press Ctrl.)
4 - The formula will work then also in Calc.
5 - The formula does not return all the distinct elements contained in the source range.
6 - It only returns the elements occurring exactly once in the source range.
7 - To also get contents occurring more than once (without repetition) cannot be achieved by a simple variation of the formula.
There may be a problem with an ambiguity of the term “distinct values”.
However, also @librebel interpreted the term the same way I did.
The above statements are demonstrated in this new version of the demo (Sheet2). Instead of column B I used column P for this. See also columns N an R.
as i understand the semantic difference between “Unique values” and “Distinct values” from the same article linked to in the comments above:
Unique values are values that occur exactly once in the original list.
Distinct values are ( Unique values plus all 1st-occurrences of duplicate values ).
In other words, Distinct values are all values from the original list, after removal of all duplicate values.@librebel: Ok.Concerning the terminology I agree with the quoted explanation. However, I often found “unique” used in the sense of “distinct” in forum contributions. With respect to the formula given in the linked article for the selection of the distinct values, I would state as a flaw that blank cells in the source range result in a 0 (zero) element in the selection. (“No blanks except at the end” must be assured.)
Anyway I would still recommend to solve tasks of the kind using either helper columns with formulae of low complexity - or interactive means as @librebel already suggested.
Inventing formulae of the kind discussed in the linked article is an intelectual adventure rather than a way to a recommendable solution, imo.
(BTW: The solution based on “my” user functions by
{=TRANSPOSE(XTEXTSPLIT("&|&";-103;XTEXTJOIN("&|&";1;A2:A100);100))} is rather efficient.)
Discussion:In a single column or row array the first cell is assumed distinct, (cell A1). Using COUNTIF you can identify is the value is distinct or a duplication of previous values in the array.
Column: Using IF(COUNTIF($A$1:A2,A2)=1,“Yes”,“No”), you can make your spreadsheet provide a True False response as required.
Row: Using IF(COUNTIF($A$1:B1,B1)=1,“Yes”,“No”), you can make your spreadsheet provide a True False response as required.
This isn’t a formula, but possibly the next option. I’ve seen several suggestions (on and off this site) about filters, but none that have done it quite like this.
Select the column values that are to be analyzed.
Then from the Menu, Data/More Filters/Standard Filters.
From the Standard Filter dialog box populate the first row of the Filter Criteria as shown.
In the dialog box that appears next(similar to screenshot below)
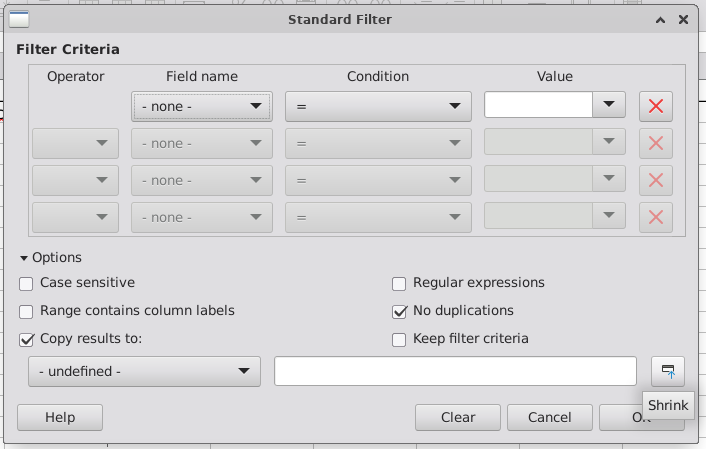
Select the check boxes as shown, and then the “Shrink” tile to select the output cell, then OK.
All the unique values will display beginning with the selected cell and continue downward.