The Text functions don’t seem to have the oomph to do this. I looked up split() but that seems like a huge effort.
Appreciate help.
R

The Text functions don’t seem to have the oomph to do this. I looked up split() but that seems like a huge effort.
Appreciate help.
R
Where do you get the information on REGEX to do this REGEX(A1;"([^;]);(.)";"$2;$1";“g”) or Find: & replace. The help in LO calc is hopeless. This is a pretty crappy Example: Example
=FIND(76;998877665544) returns 6. I looked up REGEX() in the LO calc doc and it is pretty skimpy also. Where is help on $2 and $1. I am new to this site so don’t know if this is the place to ask this stuff or do I need to ask another question!!
Just
=REGEX(A1;"([^;]*);(.*)";"$2;$1";"g")
where A1 is cell with your source “John;Smith”
Also you can use Find&Replace whith this options
Find: ([^;]*);(.*)
Replace: $2;$1
Regular expresions: ON
Update A macro function that performs the same task.
Function reorderParts(sSource As String, Optional sDelimiter As String, Optional sOrder As String) As String
Dim aTemp As Variant
Dim aOrders As Variant
Dim sTemp As String
Dim i As Integer
If IsMissing(sOrder) Then sOrder = "2,1"
aOrders = Split(sOrder,",")
If IsMissing(sDelimiter) Then sDelimiter = ";"
If InStr(sSource, sDelimiter) = 0 Then
reorderParts = sSource
Exit Function ' Empty string or no delimiter'
EndIf
aTemp = Split(sSource, sDelimiter)
sTemp = ""
For i = LBound(aOrders) To Ubound(aOrders)
If i > 0 Then sTemp = sTemp + sDelimiter
If Val(aOrders(i))<1 Or Val(aOrders(i))-1 > UBound(aTemp) Then
sTemp = sTemp + "Wrong index"
Else
sTemp = sTemp + aTemp(Val(aOrders(i))-1)
EndIf
Next i
reorderParts = sTemp
End Function
Examples of using

hello @JohnSUN,
nice work, i like to learn from such exercises, but do not feel save against simple minded creative users …
just a quick shot from memory reg. macro-function weaknesses:
you can’t debug 'em because you can’t pass the parameters, message ‘argument not optional’, you might get questions about that,
they fail to update the sheet on changes in the function, e.g. change the delimiter and the results in the sheet will stay as before, things like this overtax standard users awareness and will produce unnoticed wrong results,
and a short stresstest, trying chained ‘reorderparts’ functions and changing the delimiter produced noticeable delays for recalc with F9, changing it to “;;” and back to “;” fixed the mousepointer as ‘wait’, deleted the content of one cell and disabled input on the sheet, tried to close: crash (ver. 7.1.0.0.a0+)
you are trying to produce stable routines with unstable tools, difficult …
‘KISS’: keep it simple and stupid …
save against simple minded creative users - just a quick shot
Hmmm… This sounds like a possible solution. Not very humanistic, but this is one of the solutions 
The reorderParts function does not involve much experimentation and configuration. Select the necessary parameters for a sample from one cell, make sure that the result meets expectations, multiply the resulting formula for all data, get rid of the formula (or Copy-Paste Special-Text, or Data - Text to Columns)
Isn’t that KISS? Perhaps you and I understand this principle in different ways. In my version “stupid” is not mentioned, for me it is Keep It Small and Simple
a simple formula solution for those who are not familiar with regular expressions and don’t want to do macro programming:
B3: 'John;Smith'
C3: '=RIGHT(B3;LEN(B3)-SEARCH(";";B3)) & ";" & LEFT(B3;SEARCH(";";B3)-1)' without the quotes,
and a quick shot per macro:
sub test_re_arranging_strings
' cumbersome, 'wooden,' but it works,
' can also be run over areas with 'GetCellByPosition(i,j)' and 'run variables' for i and j,
myDoc = thisComponent
mySheet = myDoc.sheets(0) 'other values for other sheets
mycell = mysheet.getCellRangeByName("B2")
aParts = Split(mycell.string, ";")
sNewString = aParts(1) & ";" & aParts(0) 'takes only first and second split part, care if source contains more ";"
mycell1 = mysheet.getCellRangeByName("C2")
mycell1.string = sNewString
end sub 'test_re_arranging_strings
have fun …
care if source contains more “;”
What about source without any “;”?
And what about empty cells?
@JohnSUN: ‘multiple’, ‘empty’, ‘without’ “;” … as always … ‘garbage in → garbage out’,
or try to write comprehensive error handlers, and learn that users can construct more comprehensive exotics, there are simply more users around with more creativity and stupidity than programmers, ‘they win’,

seriously: when working interactively the user sees the #VALUE! messages and can correct the errors in the source data, multiple “;” i mentioned because results are produced which are not immediately noticeable as errors, but may deviate from users expectations.
reg.
b.
Yes, you are right - it’s not stupid users who are to blame for any mistake, but programmers.
Especially if instead of the usual #VALUE! stupid user will see this
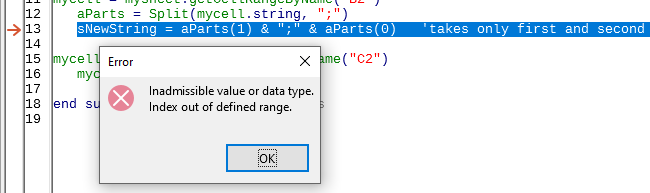
Therefore, when proposing a solution, we need to protect us as much as possible from possible reproaches. I updated my answer.