
I have maybe hundreds of English commas left after bulk word replacements. As I have replaced English words (typically proper nouns) with Persian words (CTL), the leftover commas between words are English commas (,) but I need Persian commas (،) between Persian words. A simple bulk replacement of all first type commas with the second type is not the best solution, as I have English footnotes with English commas that need to be preserved. Is there any capability in regular expressions to replace only those English commas that are placed between Persian (CTL) words, and not English words? I hope the following pictures help better clarify what I mean.
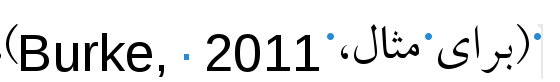
Figure 1. English words before initial replacement
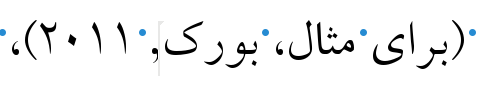
Figure 2. Commas left after Persian word(s) being replaced for English words (Note that year numeral was changed according to LO context settings)
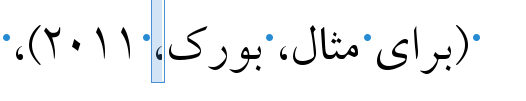
Figure 3. The highlighted comma is desired type of comma (here added manually)
 Then you may find that it’s better to do this job in a few steps: first find all occurrences of bracket, author name, comma, year - in regexp that should be this:
Then you may find that it’s better to do this job in a few steps: first find all occurrences of bracket, author name, comma, year - in regexp that should be this: