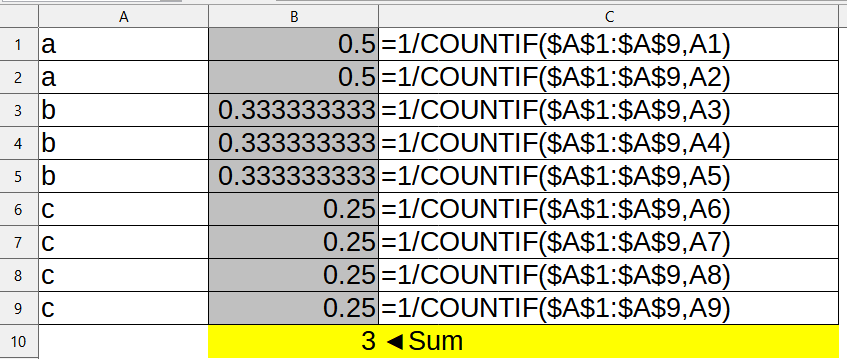
Hi Hivemind,
I have been using this array formula before to determine the number of items in a list: {=SUM(1/COUNTIF(B2:B400,B2:B400))}
However, I don’t actually understand really what it does, could someone explain how it works, please?
The reason this has become important to me (apart from simple curiosity) is that I have now long item lists of several tens of thousands of lines and the result I get is not an integer but a decimal (which for counting distinct items obviously doesn’t make sense). So, I assume this formula is a workaround and an approximation to counting items and I would like to know how accurate it is.
Thanks a lot.
PS: Here is a test file. It is an extract of the original data I am working with. I check for empty cells first then do the counting of items, which are project titles in this case. Sheet 1 shows a small deviation, Sheet 2 a significant one, and sheet 3 shows a div/0 error even though there are no empty cells in that column.
So, I don’t know if I do something fundamentally wrong or if there is an issue with the data or…
Thanks a lot for looking into this. Best regards.
Test sheet.ods