
I figured out how to make it go faster, and it does seem to work. I put the index word in the search box in the bottom left corner. Then I go to another file that has all the index words in it. I copy that word, find the word in the document, and paste it over it. This seems to remove all the index stuff. It’s lots faster but only works if you have copies of all the words without all the index entry markup on them. It’s still painful though. Find and Replace doesn’t do it though. Sigh.
Ok. I just spent 7 hours removing all the extra index entries, and then updated the word index. That looked good. I’ve attached it (it’s only a 16 page document):
b.odt (42.2 KB)
Here is the index entry dialog box on ‘puruṣa’ on page 3. It looks fine:
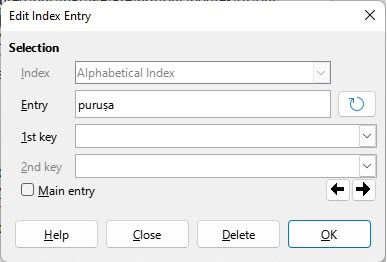
However, if I update the index again, I get extra copies of ‘puruṣa’ when I right click on the word and select Index Entry. Here is the dialog box that I got:
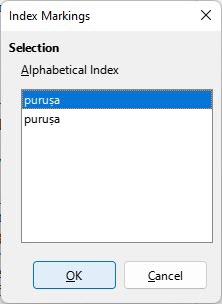
I’ve now got two Index Entries for ‘puruṣa’. What is causing this?
I updated the index by right clicking in the index at the end of the document and select Update Index.
I just tried it again using the document with all index entries removed and before I updated the index. I’ve updated the index a few times and I still only get one entry for ‘puruṣa’. There’s something different between the two files.
After I found out that I have a version that doesn’t cause multiple copies of the indexes, I created a 16 page version, the same as the one in my previous post, but this one still doesn’t create multiple indexes. I’ve attached it:
d.odt (178.8 KB)
You get this selection window when you right-click at a location where two (or more) index marks are active. This happens for example when you click near the end of Samskrtam where both Samskrtam and rtam are index keys (+).
But I can’t reproduce it even after adding a concordance file.
Personally I don’t work with concordance files because they blindly mark every occurrence of any string in their list. Sometimes this mark up is semantically meaningless (because it hits on noise words). In addition, you must be very careful to tick Word only to make sure you won’t index inadvertently a fragment of a word (e.g. with key “is”, you hit both “is” and “this”).
(+) This may be what happens on “Samskrtam” because “rtam” is also an index key. Since I have no notion of Sanskrit, I don’t know if Samskrtam is a compound word and indexing it for rtam is relevant.
Delete manually one of the occurrences and rebuild the index. If it still occurs, then there may be a bug but to report it, a short 1- or 2-page sample with systematic occurrence is needed.
EDIT after receiving d.odt
This file still has multiple index marks on keys and even the dreaded “empty key”