
Bonjour,
Je souhaiterais pouvoir faire une requête dans une base de données réalisée à partir d’un fichier “.csv” que je récupère sur un site internet Données hospitalières relatives à l'épidémie de COVID-19 (SIVIC) - data.gouv.fr, table “donnees-hospitalieres-covid19-aaaa-mm-jj-xxhxx.csv” (type de base = “texte”)
Je souhaiterais réaliser la requête sql suivante :
SELECT “dep” “dep”, “sexe” “sexe”, “jour” “jour”, SUM( “hosp” ) “hosp”, SUM( “rea” ) “rea”, SUM( “rad” ) “rad”, SUM( “dc” ) “dc” FROM “covid” WHERE “sexe” = “0” AND “jour” LIKE '2021-%" GROUP BY “jour”
Résultat : requête trop complexe, seule count(*) est pris en charge …
Ma question : comment faire pour pouvoir réaliser cette requête, j’ai l’impression que c’est le type de connexion qui pose pb … Si c’est le cas, est-il possible d’importer le fichier csv dans une bdd firebird sans de multiples manipulations, car le fichier source change tous les jours !
Merci !
Christophe
Bonjour @Cnuss
Tout d’abord désolé pour le délai (periode sans ordinateur sous la main…).
Par défaut, en effet, les bases connectées à une source “texte” n’offrent pas de fonctions évoluées puisqu’il n’y a pas de “moteur” sql.
Ce que tu demandes est toutefois possible en attachant le fichier texte dans une base Hsql (voir cette FAQ).
Après avoir attaché le fichier texte, créer une table hsql “normale” dans la base. Cette table restera vide mais il faut créer au moins un champ permettant la liaison avec la table contenant des données).
Puis insérer les deux tables dans la requête. Joindre les deux tables (il faut un champ de type compatible) puis cliquer sur le lien représentant la jointure pour définir cette dernière (gauche ou droite) de manière à afficher tous les enregistrements de la table contenant tes données).
Les fonctions de regroupement seront dès lors disponibles.
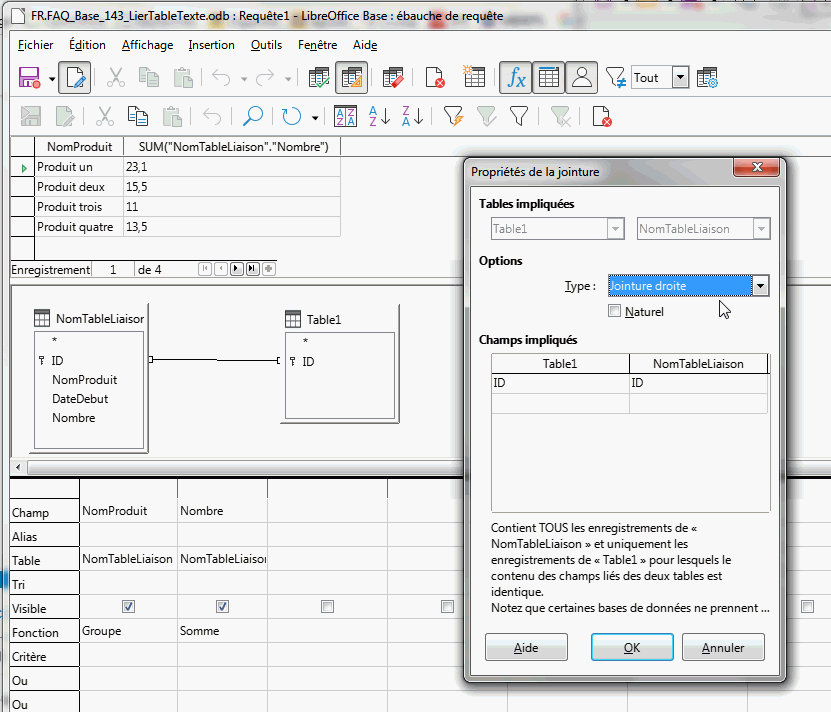
Dans la copie d’écran ci-dessous j’ai :
- utilisé la base exemple et les données de la FAQ puis
- créé Table1 vide mais avec un champ “compatible” (ID dans cet exemple)
- inséré les deux tables dans une requête
- fait la liaison puis défini la jointure comme indiqué
- défini le regroupement et la fonction somme
Cordialement
Bonjour PYS
Tu es tout pardonné pour ton retard, et surtout très grandement remercié pour ton aide bénévole et très éclairée…
Je vais regarder cela avec grande attention et espère être à la hauteur pour exploiter ton message qui offre une solution alléchante !
Je donnerai des nouvelles !
Encore merci
Christophe
Bonsoir PYS,
J’ai réussi à refaire l’exercice proposé, et j’en suis ravi car j’ai progressé dans ma connaissance de Base. Cependant, pour mon pb,
- je dois d’une part supprimer la première ligne de mon fichier csv (les titres de colonnes) mais c’est relativement rapide et donc non rédhibitoire …
- par contre, d’autre part, je me heurte au fait que mon fichier csv ne contient aucun champ d’identité, ce qui génère un message d’erreur à la création de la base, vraisemblablement car il n’y a pas création de clé ID. Et si je rajoute un champ ID, j’obtiens un message d’erreur car il n’y a pas de correspondance avec le fichier csv…
Enfin, en l’absence de champ ID, je ne peux pas lier mes deux tables …
Est-il possible de créer ce champ sans correspondance avec le fichier source csv ?
Merci …
Christophe
- Le champ d’identité n’est pas obligatoire (dans l’exemple de la FAQ tu peux simplement supprimer
“ID” INTEGER GENERATED BY DEFAULT AS IDENTITY,
du CREATE (et la première colonne du champ de données). - La liaison (toujours dans l’exemple de la FAQ) peut se faire sur le produit et dans ce cas, créer un seul champ produit dans la table1, de type caractère évidemment…
Bonjour PYS
J’ai enfin réussi, mille mercis . La question peut donc passer en “résolu”.
Quelques contraintes malgré tout à ce dispositif :
- Le fichier contient des valeurs NA, qui ne sont pas reconnues dans l’import comme valeur numérique (j’ai dû éditer le fichier csv et remplacer les NA par 0
- Pour ce que je veux faire (sélectionner puis grouper), nécessité de joindre une requête de sélection dans ma requête de “groupage”, c’est plutôt simple, mais c’est une condition nécessaire pour que cela marche.
- la taille du fichier est telle ( et les modestes performances de mon micro) que les temps de traitement sont très longs, mais rédhibitoires (la requête finale prend près de 2 mn, pour un fichier csv de quand même 197 000 lignes !!.
J’ai essayé de migrer en firebird pour voir si cela serait plus rapide, mais la table de liaison disparaît.
Je vais donc chercher une autre solution sur la base de fichiers data plus légers, mais cet exercice m’a permis de découvrir plein de potentialités vraiment géniales que je vais bien garder en mémoire !
Encore merci !
Christophe
Ok, merci pour ton “retour”.
Je suppose que tu as également exploré la piste tableur ?
Oui, en fait, je lie le résultat des requêtes dans un tableau, ce qui me permet de faire de belles courbes derrière … 
Je pourrais utiliser le tableau croisé dynamique, mais la requête BDD me semblait plus adaptée …