
There were some questions concerning kruti Dev and I am curious (and tried to help).
...
However any source I could find about the topic talks of cruti dev fonts and most of them suggest downloads. That’s useless for me. I’m not interested in using that stuff, but in understanding.
...
On the other hand a questioner is talking about conversion of cruti Dev to unicode and reverse. This should mean that kruti Dev is a way of coding for characters in a way probably especially adequate for character sets used with devanagari or related fonts.
...
Please point me to a source clearly explaining the situation in thoroughly chosen words without mixing up concepts and without making a mess of terms.
https://gist.github.com/tripleee/b82a79f5b3e57dc6a487ae45077cdbd3
In short: »kruti dev font« seems to be a pseudo-font wich is in real a kind of keyboard-makro to translate sequences of ascii-letters into some single-unicode-letter out of the Devanagari-subset.
1 Like
Yes. It’s hard. And I still miss the needed information. Got a guess.
A keyboard macro might be used on the system to get a kruti Dev multi-character code for a single stroke on a key showing a character of an alien script. This way may be created a file which our questioner would like to feed into his converter.
Now the multi-character representations need to be separated, recognised and used to get the one character (or its unicode representation) which once shall be printed or ...
BTW: The code you posted gives 171 entries. The mentioned questioner had listed 1286 entries. See attachment:
conversionListAnniruddhaMohod.ods (20.6 KB)
… and filtered [x]case sensitive … [x]no duplicates … the list has 1008 entries!
And also a number of extra-replacements which are applied after the first-processing.
And entries aren’t sorted according to length, for example lines 35 & 36

That means the character U+0936 will be replaced always, but U+0936&U+093E never.
If we look at the assignments we find at least some kruti Dev codes which are case sensitive. But still this isn’t the most relevant questions.
- How are the codes per character separated?
- How is made sure that longer codes aren’t destroyed by the replacement of shorter ones starting with an identical part when running a conversion in situ?
- (Different category:) Why is such a complicated code still used?
Why isn’t there a standard document defining the system clearly?
Such documents exist for some dfecades now for unicode in general and for utf-8 , utf-16, too.
that means the list should first sorted by »len( column A) descending« and then in alphabetic-order
Yes, but why did the questioner not regard this. He claimed nevertheless that his code worked correctly with selected text.
Imaging you have nothing but a keyboard with english-layout.
Ask the questioner!
Why?
Who would and who could type (from natural memory) the mystic codes on an English keyboard.
Every perl-programmer would be in best position to try😉
1 Like
Driven by curiosity about this thread, I tried to understand what is at stake.
According to public information, Kruti Dev fonts are not Unicode. They are clearly described as legacy fonts. This means they are 256-glyph sets. A conventional mapping on a “Remington” keyboard has been defined to select the required glyphs.
In technical words, a key press produces a “common” English code out of ASCII and perhaps Latin-1 blocks. This is obviously not Unicode-compliant where Devanagari is assigned U+0900-U+097F.
As a legacy fonts, Kruti Dev is probably sent into the PUA.
Now, I wonder if the whole discussion is about trying to re-canonise document encoding by translating the ASCII transliteration to the Devanagari block. If this is so, I think the AutoCorrect approach is not the best because you don’t control explicitly precedence between rules. IMHO, processing the .fodt form of the document with a macro generator is probably more efficient and reliable.
1 Like
I tried to help with the conversion of Kruti dev to Unicode. But soon realized that it is not worth it.
Spell checking for Kruti Dev text in LibreOffice does not function as expected because punctuation marks are inherently part of the font’s input method. For example, consider adding these 2 words “अनिरुद्ध मोहोड” to the custom dictionary. Internally, they are stored as vfu#) eksgksM The word मोहोड will be correctly recognized as valid. Hunspell interprets the word अनिरुद्ध as vfu#) since Kruti Dev is a non-Unicode font. Hunspell detects punctuation marks such as “#)” in the transliterated form and treats them as separator like space. When it checks the word against its database, it evaluates only “vfu” and ignores “#)”, leading to an incorrect assessment.
Therefore, even if two words are added to the custom dictionary, only one may be validated correctly. In other words, approximately 50% of the words will be marked as incorrect even for valid words, rendering the spell check ineffective for Kruti Dev text.
The message is clear: it is time to move away from legacy fonts such as Kruti Dev and adopt Unicode. Arguments such as “we are accustomed to Kruti Dev”, “looks nice and we love it” or “our existing documents use that font” are obsolete.
3 Likes
Printscreen from FontForge for font Kruti Dev 055, the Latin characters and punctuations are “redesigned” by KrutiDev characters.
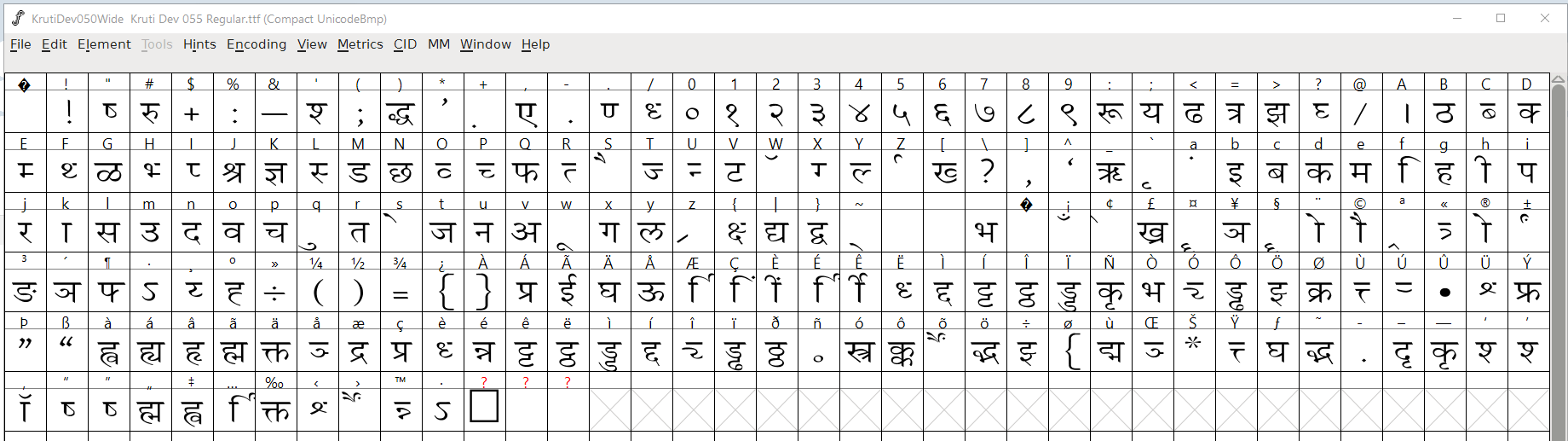
Now I understand why it is problematic for dictionaries, like @shantanuo mentioned.
This kind of remapping was the only available solution in the era of 256-glyph only character sets. Unicode has been developed to offer a Universal consistent solution exempt of “glitches”. I.e. those “exotic” fonts can only be used after prior agreement between sender and receiver (e.g. a warning about the encoding and unambiguous designation of the font to be used).
Presently, the only viable and reliable approach is to strictly adhere to Unicode. Of course, there is a price: any character beyond the ASCII set needs more than one byte, 3 bytes in Devanagari case (excluding Vedic extension).