I have problems using XMATCH and MATCH functions in neighboured cells.
I have two sheets in 1 document called t01 and Saldo.
In “t01” project times are (ordered by day) collected. And if a project is finished it is marked with a special string.
| Date | Start | End | TestValue | Text | hours |
|---|---|---|---|---|---|
| Jänner 2024 | |||||
| 01.01.2024 | 07:00 | 08:00 | P00000 | test | 1 |
| 08:00 | 09:00 | P15000 | test | 1 | |
| 12:00 | 13:00 | P17001 | test | 1 | |
| 15:00 | 16:00 | P24001 | test | 1 | |
| 17:00 | 19:00 | P15000 | test | 2 | |
| §§fertig P15000 | |||||
| 02.01.2024 | 15:00 | 16:00 | P24001 | test | 1 |
| 17:00 | 19:00 | P15000 | test | 2 | |
| §§fertig P15000 |
In Saldo the sum of hours for each project calculated. In addition I wanted the date when a project is finished. During testing I got some strange results, which I summarized in row 14-20 in “Saldo”.
First column shows the functions used, second and third columns contain the result. And in forth column I wrote the expected result of column three.
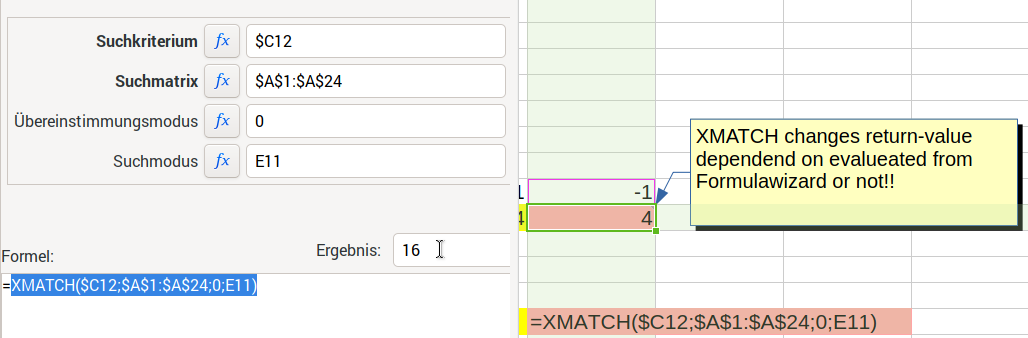
For me it seems that the result in column three is not calculated correctly, but taken from column two, but I am not sure, wether I made a mistake or somehow misunderstood XMATCH function.
| get year from table name | 2024 | 18.10.2020 | |||
|---|---|---|---|---|---|
| MATCH | XMATCH ↑ | ||||
| hours | closed | closed test | |||
| Testvalues | |||||
| P00000 | 1 | ||||
| P15000 | 5 | 01.01.2024 | 01.01.2024 | ||
| P17002 | 0 | ||||
| P24001 | 2 | ||||
| MATCH | 9 | 9 | |||
| XMATCH ↓ | 9 | 9 | |||
| XMATCH ↑ | 15 | 15 | |||
| MATCH XMATCH ↑ | 9 | 9 | 15 | ||
| XMATCH ↑ MATCH | 15 | 15 | 9 | ||
| XMATCH ↓ XMATCH ↑ | 9 | 9 | 15 | ||
| XMATCH ↑ XMATCH ↓ | 15 | 15 | 9 |
For calculating I use following formulars:
MATCH: =MATCH(CONCATENATE("§§fertig “;$B$7);t01.$E$1:$E$50;0)
XMATCH downwards: =XMATCH(CONCAT(”§§fertig “;$B$7);t01.$E$1:$E$50;0)
XMATCH upwards: =XMATCH(CONCATENATE(”§§fertig ";$B$7);t01.$E$1:$E$50;0;-1)
I also send you the calc document for reproducing the problem.
LO-XMATCH-p_2024.ods (16.7 KB)
Kind regards, Ulrike